Comment anonymiser des données personnelles ?
Publié le 13 mars 2023
Les recherches menées au sein de Télécom SudParis par Maryline Laurent, professeure directrice du département RST et Nesrine Kâaniche, enseignante-chercheuse en informatique démontrent que nos données personnelles ne sont pas infaillibles à l’anonymat. Dans la tribune "Comment anonymiser des données personnelles", publiée par The Conversation, nos deux chercheuses prouvent les limites de cette anonymisation.
En 1997, la chercheuse du MIT Latanya Sweeney utilisait une base de données de santé déclarée « anonymisée » et la recoupait avec les informations de la base électorale de la ville de Cambridge, dans le Massachussetts aux États-Unis, pour réidentifier le dossier médical du gouverneur de l’État, William Weld – et déduire qu’il souffrait d’un cancer.
En 2010, les données de recensement aux États-Unis, bien qu’elles aient été déclarées anonymisées, ont permis à des chercheurs de réidentifier massivement des individus, en particulier des adolescents transgenres.
Yves-Alexandre De Montjoye a démontré en 2013 que nos données de géolocalisation étaient très identifiantes : 4 points de géolocalisation collectés à différents moments de la journée suffisent à réidentifier avec 95 % de chance de succès un individu dans un jeu de données rassemblant les traces des déplacements de 1,5 million personnes.
De nos jours, quasiment tous les acteurs fournissant un service, qu’ils soient une entreprise, une association, une collectivité ou une administration, collectent les données personnelles des utilisateurs ou usagers : adresses postales, noms, prénoms, biens achetés, montants… Ces données personnelles sont utiles pour profiler les clients, vendre des biens ajustés à leurs besoins ou pour valoriser économiquement ces données, par exemple avec de la publicité ciblée.
Les raisons pour qu’un fournisseur de services anonymise ses données sont multiples, mais c’est avant tout dans un souci de se conformer au règlement Européen, le « RGPD », qui se veut protecteur de la vie privée des citoyens. Si le fournisseur de services veut conserver des données au-delà de la durée réglementaire (36 mois par exemple pour les opérations de prospection commerciale) ou s’il ne dispose pas des moyens techniques pour garantir la sécurité de ces données, il doit les « anonymiser », pour que ces données ne puissent plus être reliées à une personne.
Le « risque zéro » n’existe pas
En pratique, il existe plusieurs techniques pour anonymiser les données, chacune avec leurs limites. Les méthodes et outils peuvent être contournés par des individus malveillants disposant de suffisamment de données auxiliaires et de capacités pour effectuer des attaques.
De plus, en anonymisant des données, on « dégrade leur qualité », c’est-à-dire qu’elles perdent peu à peu de leur richesse d’information (on approxime une date de naissance par un âge par exemple). Si les données sont trop dégradées, elles deviennent inexploitables et donc inutiles pour une entreprise – autant ne pas les archiver.
Pourquoi est-il si compliqué d’anonymiser ? Tout simplement car il n’existe pas de méthode générique : on n’anonymise pas de la même façon des données de géolocalisation retraçant les déplacements des personnes, que la dynamique des relations dans un réseau social, ou encore des données de santé.

De plus, si des données dégradées permettent de calculer de façon satisfaisante le volume de personnes amenées à se déplacer quotidiennement entre une ville d’Île-de-France et Paris, elles ne permettent pas forcément de mener des recherches médicales, que l’on veut aussi précises que possible.
Comment réidentifier des individus à partir de leurs données personnelles ?
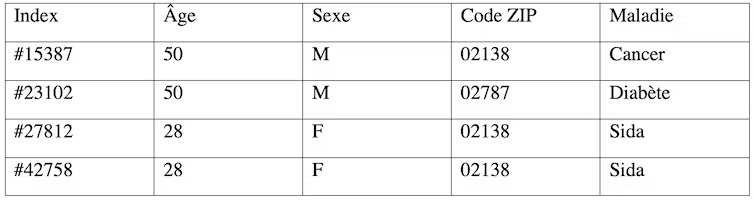
Supposons que nous disposions du jeu de données anonymisées du tableau 1 qui illustre de façon très simplifiée les données ayant conduit à la réidentification du gouverneur du Massachussetts William Weld.
Supposons par ailleurs que nous nous soyons procurés la liste des électeurs avec leurs noms et prénoms, présentée dans le tableau 2.
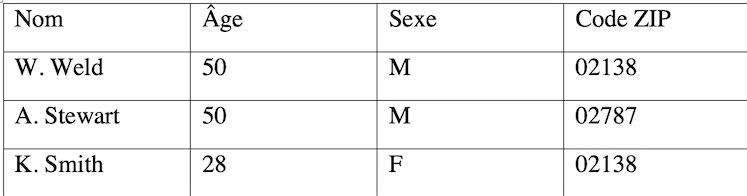
Il est possible, par corrélation entre les deux tableaux, de déduire que le gouverneur W. Weld correspond à l’enregistrement #25587 du tableau 1 (et par déduction qu’il souffre d’un cancer). Cette attaque de réidentification est appelée plus scientifiquement « attaque d’individualisation ».
Quant à l’« attaque par inférence », elle consiste à déduire de certaines valeurs des attributs (âge, sexe, code ZIP) des valeurs pour d’autres attributs (maladie). Par exemple, grâce au tableau 1, on peut déduire que toutes les femmes de 28 ans résidant dans la zone identifiée par le code ZIP 02138, et faisant partie de l’étude car elles ont effectué des soins dans un certain hôpital, souffrent du sida.
Des méthodes d’anonymisation généralement intuitives, mais au succès tout relatif
Une première méthode, le K-anonymat (K étant un paramètre à fixer), consiste à empêcher l’individualisation des individus en s’assurant qu’au moins K individus ont les mêmes caractéristiques et que toute tentative d’individualisation ne permet pas d’isoler un individu parmi K.
Sur le tableau ci-dessous, par exemple, K = 2 signifie qu’au moins 2 personnes ont les mêmes attributs âge et sexe, ainsi si un attaquant a connaissance qu’un individu de 26 ans de sexe masculin fait partie du jeu de données, il ne pourra pas établir de corrélation et savoir à quelle ligne correspond cet individu (#52140 ou #53856). Il ne pourra donc pas le réidentifier.
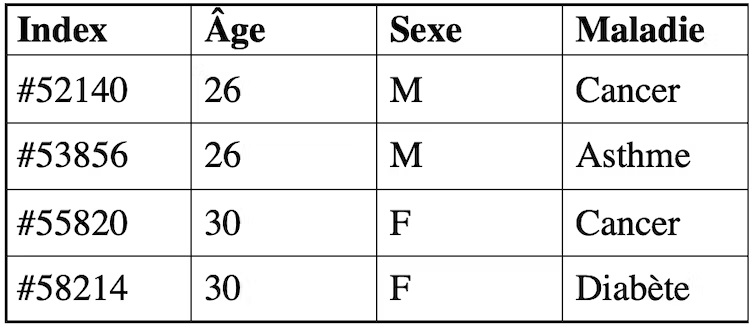
Plus K est grand, plus la méthode offre de garanties en termes de confidentialité. On notera que pour obtenir le résultat du 2-anonymat, il est possible d’appliquer une transformation par généralisation pour diminuer la précision d’une information, la date de naissance d’un individu devient par exemple son âge.
Pour empêcher l’attaque par inférence, qui vise à déduire par exemple de quelle maladie souffre un individu ou une catégorie d’individus, il existe la méthode de L-diversité, « L » étant un paramètre à fixer. Il s’agit de s’assurer que chaque groupe d’individus constitué suite au K-anonymat ne pointe pas vers une maladie unique, mais au moins L maladies possibles. Ainsi, dans l’exemple simple, l’attaquant ne pourra pas déduire qu’un individu de 26 ans de sexe masculin souffre d’une maladie précise, mais qu’il a soit un cancer, soit de l’asthme.
Citons aussi la T-proximité qui appartient à la famille du K-anonymat et de la L-diversité et qui vérifie des éléments statistiques sur la distribution des valeurs. Plus T est proche de 1 (T entre 0 et 1), plus la distribution est similaire à celle de la base réelle.
Enfin, il existe une autre famille de méthodes, très utilisée et largement plébiscitée par les GAFAM. Elle repose sur le principe de la confidentialité différentielle (« differential privacy » en anglais) qui consiste à introduire du bruit de façon statistique pour altérer la précision des informations contenues. Certes, elle a été utilisée pour anonymiser les données de recensement des Etats Unis de 2020, mais pour le besoin spécifique d’anonymiser des bases de données, elle souffre de limitations comme de dégrader trop fortement les données de recensement.
Pseudonymiser au lieu d’anonymiser
Anonymiser étant un procédé difficile à maîtriser, les entreprises souvent préfèrent conserver une très bonne utilité de leurs données et optent pour la pseudonymisation plutôt que l’anonymisation. La « pseudonymisation » consiste à supprimer les éléments directement identifiants comme un nom, un prénom ou une adresse complète pour les remplacer par un identifiant aléatoire semblable à un pseudonyme. Elle ne garantit donc pas une bonne résistance aux attaques, comme cela a été démontré par L. Sweeney en 1997 sur le jeu de données ayant permis de réidentifier le gouverneur du Massachussetts.
Les entreprises qui ne peuvent pas prouver que leur jeu de données est suffisamment résistant à des attaques par individualisation, inférence et corrélation doivent alors démontrer que le risque de réidentification est maitrisé, ce qui dépend des données et du contexte considérés. N’oublions pas que les entreprises, comme les établissements, les collectivités… qui traitent quantité de données personnelles ont une obligation de moyens, pas de résultats.
Nous tenons à remercier Louis-Philippe Sondeck, fondateur de Clever Identity, pour l’éclairage apporté sur les pratiques en entreprises.
Cet article est republié à partir de The Conversation dans le cadre d’un partenariat avec l’Institut Mines-Télécom. Lire l’article original.
